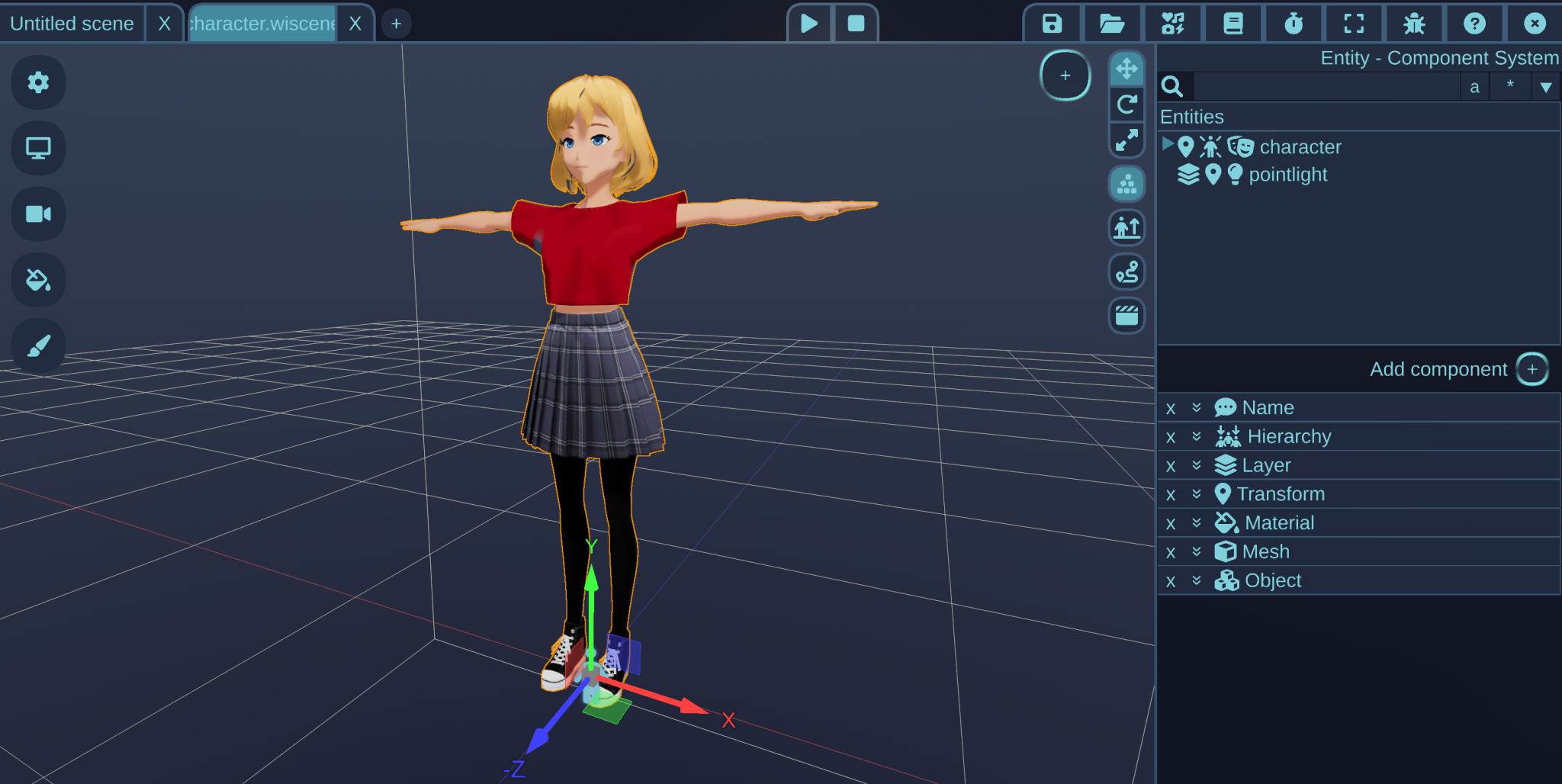
Lightweight editor
Edit models and run scripts with a standalone editor. No internet connection required, no strings attached.
 Downloads ->
Downloads ->
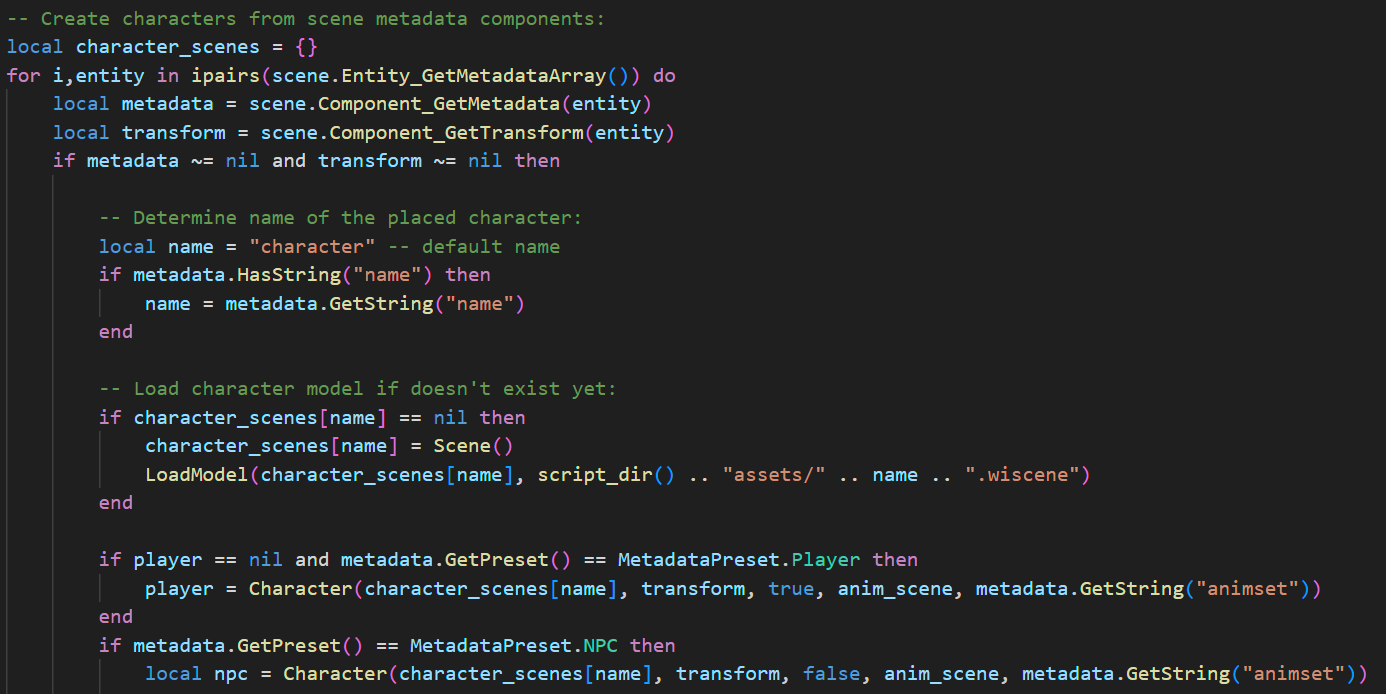
Code-oriented
Enjoy quick and easy Lua scripting, or dive as low level as you want with C++.
 Source code and samples ->
Source code and samples ->
VRM characters
Get started with custom characters in your projects quickly and easily!
 Create characters in VRoid studio ->
Create characters in VRoid studio ->
Realistic rendering
High quality effects, physically based materials, real-time lighting, ray tracing, terrain generation and more…
 Videos ->
Videos ->